第二章:信息的表示和处理
本章介绍了计算机上如何表示数字和其他形式数据的基本属性,以及计算机对这些数据执行操作的属性。
2.1 信息存储
2.1.1 十六进制表示法
2.1.2 字数据大小
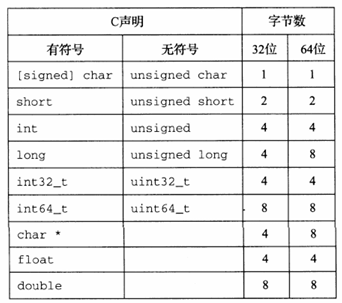
基本c数据类型的典型大小(以字节为单位)。
分配的字节数受程序是如何编译的影响而变化。
本图给出的是32位和64位程序的典型值
2.1.3 寻址和字节顺序
关于大端法和小端法
- 最低有效字节在最前面的方式,称为小端法(little endian)
- 最高有效字节在最前面的方式,称为大端法(big endian)
假设变量x的类型为int,位于地址0x100处,它的十六进制值为0x012345670 地址范围0x100 ~ 0x103的字节顺序依赖于机器的类型:

我们可以执行下面这段程序。打印程序对象的字节表示
# include <stdio.h>
int main(){
typedef unsigned char *byte_pointer;
void show_bytes(byte_pointer start, size_t len){
size_t i;
for(i=0;i<len;i++)
printf("%.2x",start[i]);
//C格式化指令 %.2x 表明整数必须用至少两个数字的十六进制格式输出。
printf("\n");
}
void show_int(int x){
show_bytes((byte_pointer) &x, sizeof(int));
}
void show_float(float x){
show_bytes((byte_pointer) &x, sizeof(float));
}
void show_pointer(void *x){
show_bytes((byte_pointer) &x, sizeof(void *));
}
void test_show_bytes(int val){
int ival = val;
float fval = (float) ival;
int *pval = &ival;
show_int(ival);
show_float(fval);
show_pointer(pval);
}
test_show_bytes(12345);
return 0;
}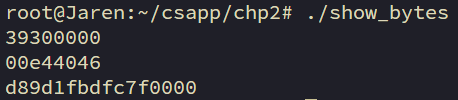
参数12345的十六进制表示为0x00003039
在我的Linux 64上,最低有效字节值0x39最先输出,这说明它是小端法机器
练习题 2.58
写一个函数返回所使用机器的大小端类型,示例代码如下:
// 示例代码
#include <stdio.h>
int is_little_endian(void){
union w
{
int a;
char b;
}c;
c.a = 1;
return (c.b == 1); // 小端返回TRUE,大端返回FALSE
}
int main(int argc, char *argv[]) {
if(is_little_endian())
printf("Little Endian\n");
return 0;
}在Ubuntu 22.04.5 LTS x86_84环境下,输出:Little Endian
解释:
- 联合体(Union):在 C 语言中,联合体允许多个变量共享同一内存位置。在这段代码中,
union w里面有一个int a和一个char b,它们共用相同的内存空间。关键是对 a 或 b 的修改会影响另一个。 - 给
a赋值为1:当你把1赋值给a时,内存中的表示方式会因字节序的不同而有所不同:- 小端字节序:最低有效字节(LSB)存储在最前面,所以
1的内存表示就是0x01存储在b所代表的位置。 - 大端字节序:最高有效字节(MSB)存储在最前面,所以
1的内存表示是0x00存储在b所代表的位置。
- 小端字节序:最低有效字节(LSB)存储在最前面,所以
- 检查
b的值:然后程序检查b的值。如果是小端字节序,b将是1;如果是大端字节序,b将是0。因此,is_little_endian()函数返回1表示小端字节序,返回0表示大端字节序。
2.1.4 表示字符串
C语言中字符串被编码为一个以null(其值为0)字符结尾的字符数组。每个字符都由某个标准编码来表示,最常见的是ASCII字符码。
2.1.5 表示代码
计算机系统的一个基本概念就是,从机器的角度来看,程序仅仅只是字节序列
2.1.6 布尔代数
2.1.7 C语言中的位级运算
C语言支持按位布尔运算
|或&与~取反^异或
2.1.8 C语言中的逻辑运算
逻辑运算符:
||或&&与!非
逻辑运算很容易和位级运算相混淆,但是它们的功能是完全不同的。
逻辑运算认为所有非零的参数都表示TRUE,而参数0表示FALSE,它们返回1或者0,分别表示结果为TRUE或者为FALSE。
以下是一些表达式求值的示例。
| 表达式 | 结果 |
|---|---|
| ! 0x41 | 0x00 |
| ! 0x00 | 0x01 |
| !! 0x41 | 0x01 |
| 0x66 && 0x55 | 0x01 |
| 0x66 || 0x55 | 0x01 |
逻辑运算符&&和||与它们对应的位级运算&和|之间第二个重要的区别是
如果对第一个参数求值就能确定表达式的结果,那么逻辑运算符就不会对第二个参数求值。
因此,表达式a&&5/a将不会造成被零除,而表达式p&&*p++也不会导致间接引用空指针。
2.1.9 C语言中的位移运算
- 左移
- 逻辑右移:在左端补k个0
- 算术右移: 在左端补k个最高有效位的值
| 操作 | 值 |
|---|---|
| 参数 X | [01100011] [10010101] |
| x << 4 | [0011000] [01010000] |
| x >> 4 (逻辑右移) | [00000110] [00001001] |
| x >> 4 (算数右移) | [00000110] [11111001] |
C语言标准并没有明确定义对于有符号数应该使用哪种类型的右移——算术右移或者逻辑右移都可以。
不幸地,这就意味着任何假设一种或者另一种右移形式的代码都可能会遇到可移植性问题。
然而,实际上,几乎所有的编译器/机器组合都对有符号数使用算术右移,且许多程序员也都假设机器会使用这种右移。
另一方面,对于无符号数,右移必须是逻辑的。
2.2 整数表示
整数的数据与算术操作术语。下标砂表示数据表示中的位数
2.2.1 整数数据类型
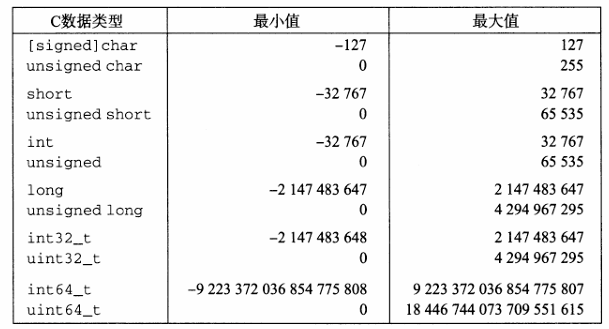
32位程序上C语言整型数据类型的典型取值范围

64位程序上C语言整型数据类型的典型取值范围

C语言的整型数据类型的保证的取值范围。
C语言标准要求这些数据类型必须至少具有这样的取值范围
2.2.2 无符号数的编码
2.2.3 补码编码
C语言标准并没有要求要用补码的形式来表示有符号整数,但是几乎所有的机器都是这么做的。
2.2.4 有符号数和无符号数之间的转换
C语言允许在各种不同的数字数据类型之间做强制类型转换。
对于大多数C语言的实现,处理同样字长的有符号数和无符号数之间相互转换的一般规则是:数值可能会改变,但是位模式不变。
这个特性就会导致部分数在转换前后值不相同
例如:
short int v =-12345;
unsigned short uv = (unsigned short) v;
printf("v = %d , uv = %u\n", v, uv);在一台采用补码的机器上,上述代码会产生如下输出:
v = -12345, uv = 53191
我们看到,强制类型转换的结果保持位值不变,只是改变了解释这些位的方式。
-12345的16位补码表示与53191的16位无符号表示是完全一样的:1100 1111 1100 0111
unsigned u = 4294967295u; /* UMax */
int tu = (int) u;
printf("u = %u, tu = %d\n", u, tu);在一台采用补码的机器上,上述代码会产生如下输出:
u = 4294967295, tu = -1
我们可以看到,对于32位字长来说,无符号形式的4294967295(UMax32)和补码形式的-1的位模式是完全一样的。
将unsigned强制类型转换成int,底层的位表示保持不变
原书描述了转化公式,详情参考原文2.2.4
2.2.5 C语言中的有符号数和无符号数
通常,大多数数字都默认为是有符号的。例如,当声明一个像12345或者0x1A2B这样的常量时,这个值就被认为是有符号的。
要创建一个无符号常量,必须加上后缀字符u或者U,例如, 12345U或者0x1A2Bu。
由于C语言对同时包含有符号和无符号数表达式的这种处理方式,出现了一些奇特的行为。
当执行一个运算时,如果它的一个运算数是有符号的而另一个是无符号的,那么C语言会隐式地将有符号参数强制类型转换为无符号数,并假设这两个数都是非负的,来执行这个运算。
就像我们将要看到的,这种方法对于标准的算术运算来说并无多大差异,但是对于像<和>这样的关系运算符来说,它会导致非直观的结果。
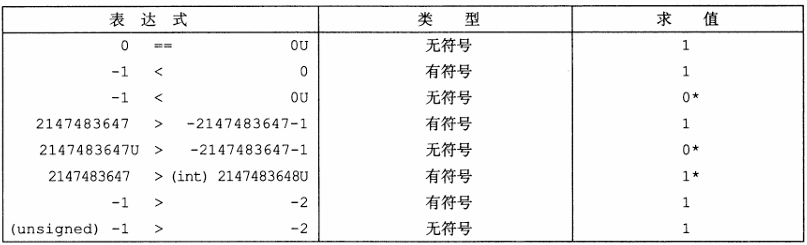
非直观的情况标注了
*
考虑比较式-1<0U
因为第二个运算数是无符号的,第一个运算数就会被隐式地转换为无符号数,因此表达式就等价于4294967295U < 0U,因为T2U(-1)=UMax
2.2.6 扩展一个数字的位表示
简单来说,无符号数的扩展是添加0,补码数值的扩展是扩展最高有效位(符号位)
详情参见原文2.2.6
2.2.7 截断数字
减少一个数字的位数的操作就是截断数字
依然遵循着数值可能会改变,但是位模式不变的规则。
我们用这段程序为例,解释一下原理:
int x = 53191;
short sx = (short) x; /*-12345*/
int y = sx; /*-12345*/当我们把x强制类型转换为short时,我们就将32位的int截断为了16位的short int。
就像前面所看到的,这个16位的位模式就是-12345的补码表示。当我们把它强制类型转换回int时,符号扩展把高16位设置为1,从而生成-12345的32位补码表示。
原文中采用了取模运算的方式定义了截断数字的运算函数,这个过程非常的有趣且巧妙。
2.2.8 关于有符号数与无符号数的建议
书中的两道例题很好的说明了了某些由于隐式强制类型转换和无符号数据类型造成的细微的错误
练习题2.25
考虑下列代码,这段代码试图计算数组a中所有元素的和,其中元素的数量由参数length给出。
/*WARNING:This is buggy code*/
float sum_elements(float a[], unsigned length){
int i;
float result = 0;
for(i = 0; i <= length-1; i++){
result += a[i];
}
return result;
}当参数length等于0时,运行这段代码应该返回0.00。
但实际上,运行时会遇到一个内存错误。
请解释为什么会发生这样的情况,并且说明如何修改代码。
答:
设计这个问题是要说明从有符号数到无符号数的隐式强制类型转换很容易引起错误。
将参数length作为一个无符号数来传递看上去是件相当自然的事情,因为没有人会想到使用一个长度为负数的值。停止条件i<=length-1看上去也很自然。但是把这两点组合到一起,将产生意想不到的结果!
因为参数length是无符号的,计算0-1将使用无符号运算,这等价于模数加法。结果得到UMax。 <=比较同样使用无符号数比较,而因为任何数都是小于或者等于UMax的,所以这个比较总是为真!
因此,代码将试图访间数组a的非法元素。
有两种方法可以改正这段代码,其一是将length声明为int类型,其二是将for循环的测试条件改为i<length。
练习题2.26
现在给你一个任务,写一个函数用来判定一个字符串是否比另一个更长。前提是你要用字符串库函数strlen,它的声明如下:
/* Prototype for library function str|en */
size_t strlen(const char *s) ;最开始你写的函数是这样的:
/* Determine whether string s is Ionger than string t */
/* WARNING: This function is buggy */
int strlonger(char *s, Char *t) {
return strlen(s) - strlen(t) > 0;
}当你在一些示例数据上测试这个函数时,一切似乎都是正确的。进一步研究发现,在头文件stdio.h中数据类型size_t是定义成unsignedint的。
A.在什么情况下,这个函数会产生不正确的结果?
B.解释为什么会出现这样不正确的结果。
C.说明如何修改这段代码好让它能可靠地工作。
答:
这个例子说明了无符号运算的一个细微的特性,同时也是我们执行无符号运算时不会意识到的属性。这会导致一些非常棘手的错误。
A:当s比t短的时候,该函数会不正确地返回1。
B:由于strlen被定义为产生一个无符号的结果,差和比较都采用无符号运算来计算。当s比t短的时候, strlen(s)-strlen(t)的差会为负,但是变成了一个很大的无符号数,且大于0。
C:将测试语句改成:return strlen(s) > strlen(t)。
2.3 整数运算
2.3.1 无符号加法
无符号数加法、溢出检查、无符号数求反的具体算法见原文
2.3.2 补码加法
补码加法、溢出检查具体算法见原文
2.3.3 补码的非
补码非的位级表示:
- 方法一:对每一位求补,再对结果加1。
- 方法二:建立在将位向量分为两部分的基础之上,假设k是最右边的1的位置,我们对位k左边的所有位取反即可。
这里我们要知道一点就是:最小补码(TMin)是自己加法的逆元
也就是说:TMin = -TMin

2.3.4 无符号乘法
2.3.5 补码乘法
简单来说,乘法与加法类似,按照数学原理进行乘法,最后进行取模运算处理溢出。
2.3.6 乘以常数
乘以2的幂
进行向左移位运算
2.3.7 除以常数
除以2的幂也可以用移位运算来实现,只不过我们用的是右移,而不是左移。
无符号和补码数分别使用逻辑移位和算术移位来达到目的。
2.3.8 关于整数运算的最后思考
正如我们看到的,计算机执行的"整数"运算实际上是一种模运算形式。
表示数字的有限字长限制了可能的值的取值范围,结果运算可能溢出。
我们还看到,补码表示提供了一种既能表示负数也能表示正数的灵活方法,同时使用了与执行无符号算术相同的位级实现,这些运算包括像加法、减法、乘法,甚至除法,无论运算数是以无符号形式还是以补码形式表示的,都有完全一样或者非常类似的位级行为。
我们看到了C语言中的某些规定可能会产生令人意想不到的结果,而这些结果可能是难以察觉或理解的缺陷的源头。
我们特别看到了unsigned数据类型,虽然它概念上很简单,但可能导致即使是资深程序员都意想不到的行为。我们还看到这种数据类型会以出乎意料的方式出现,比如,当书写整数常数和当调用库函数时。
2.4 浮点数
这一小节我们必须要掌握IEEE浮点标准
2.4.1 二进制小数
2.4.2 IEEE浮点表示

2.4.3 数字示例
2.4.4 舍入
2.4.5 浮点运算
注意:浮点加法不满足结合律
2.4.6 C语言中的浮点数
所有的C语言版本提供了两种不同的浮点数据类型: float和double.
在支持IEEE浮点格式的机器上.这些数据类型就对应于单精度和双精度浮点。另外,这类机器使用向偶数舍入的方式。
不幸的是,因为C语言标准不要求机器使用IEEE浮点,所以没有标准的方法来改变舍入方式或者得到诸如-0、 +∞、-∞或者NaN之类的特殊值。大多数系统提供include('.h')文件和读取这些特征的过程库,但是细节随系统不同而不同。
2.5 小结
计算机将信息编码为位(比特),通常组织成字节序列。有不同的编码方式用来表示整数、实数和字符串。不同的计算机模型在编码数字和多字节数据中的字节顺序时使用不同的约定
C语言的设计可以包容多种不同字长和数字编码的实现。64位字长的机器逐渐普及,并正在取代统治市场长达30多年的32位机器。由于64位机器也可以运行为32位机器编译的程序,我们的重点就放在区分32位和64位程序,而不是机器本身。64位程序的优势是可以突破32位程序具有的4GB地址限制。
大多数机器对整数使用补码编码,而对浮点数使用IEEE标准754编码。在位级上理解这些编码,并且理解算术运算的数学特性,对于想使编写的程序能在全部数值范围上正确运算的程序员来说,是很重要的。
在相同长度的无符号和有符号整数之间进行强制类型转换时,大多数C语言实现遵循的原则是底层的位模式不变。在补码机器上,对于一个w位的值,这种行为是由函数T2U和U2T,来描述的。C语
言隐式的强制类型转换会出现许多程序员无法预计的结果,常常导致程序错误。
由于编码的长度有限,与传统整数和实数运算相比,计算机运算具有非常不同的属性。当超出表示范围时,有限长度能够引起数值溢出。当浮点数非常接近于0.0,从而转换成零时,也会下溢。
和大多数其他程序语言一样, C语言实现的有限整数运算和真实的整数运算相比,有一些特殊的属性。例如,由于溢出,表达式x*x能够得出负数。但是,无符号数和补码的运算都满足整数运算的许多其他属性,包括结合律、交换律和分配律。这就允许编译器做很多的优化。例如,用(x<<3)-x取代表达
式7*x时,我们就利用了结合律、交换律和分配律的属性,还利用了移位和乘以2的幂之间的关系。
我们已经看到了几种使用位级运算和算术运算组合的聪明方法。例如,使用补码运算, ~x+1等价于-x.另外一个例子,假设我们想要一个形如[0, ⋯, 0, 1, ⋯, 1]的位模式,由w-k个0后面紧跟着k个1组成。这些位模式有助于掩码运算。这种模式能够通过C表达式(1<<k)-1生成,利用的是这样一个属性,即我们想要的位模式的数值为2^k-1。例如,表达式(1<<8)-1将产生位模式0xFF。
浮点表示通过将数字编码为 × * 2^y的形式来近似地表示实数。最常见的浮点表示方式是由IEEE标准754定义的。它提供了几种不同的精度,最常见的是单精度(32位)和双精度(64位)。IEEE浮点也能够表示特殊值+∞、-∞和NaN
必须非常小心地使用浮点运算,因为浮点运算只有有限的范围和精度,而且并不遵守普遍的算术属性,比如结合性。
以上小结内容节选自原文2.5